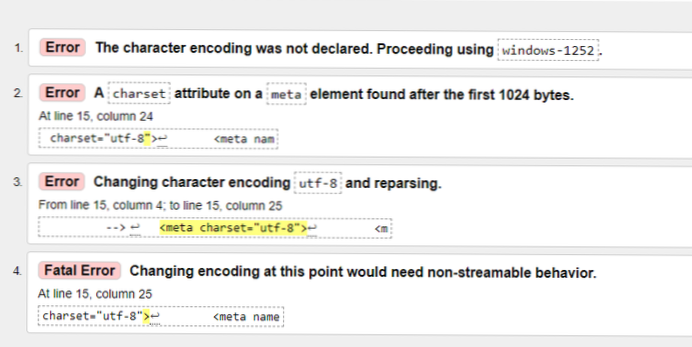
- Hvordan slipper jeg af med UTF-8-fejl?
- Hvad er UTF8-fejl?
- Hvordan ændrer jeg kodningen til UTF-8?
- Hvordan opbevares UTF8?
- Hvordan løser jeg Unicode-problemer?
- Hvilke tegn er ikke tilladt i UTF-8?
- Hvad betyder UTF-8 i HTML?
- Hvorfor erstattede UTF-8 ascii?
- Er UTF-8 det samme som Ascii?
- Hvad er forskellen mellem ANSI og UTF-8?
- Hvorfor bruges UTF-8?
- Hvad UTF-8 betyder?
Hvordan slipper jeg af med UTF-8-fejl?
2 svar
- Brug et tegnsæt, der accepterer enhver byte, såsom iso-8859-15, også kendt som latin9.
- hvis output skal være utf-8 men indeholder fejl, skal du bruge fejl = ignorere -> fjerner lydløst ikke utf-8 tegn eller fejl = udskift -> erstatter ikke utf-8 tegn med en erstatningsmarkør (normalt ? )
Hvad er UTF8-fejl?
UTF-8 er det dominerende tegnkodningsformat på World Wide Web. Denne fejl opstår, fordi den software, du bruger, gemmer filen i en anden type kodning, såsom ISO-8859, i stedet for UTF-8. Der er forskellige løsninger, du kan bruge til at ændre din fil til UTF-8-kodning.
Hvordan ændrer jeg kodningen til UTF-8?
Klik på Værktøjer, og vælg derefter Webindstillinger. Gå til fanen Kodning. I rullemenuen til Gem dette dokument som: vælg Unicode (UTF-8). Klik på Ok.
Hvordan opbevares UTF8?
Når software, der læser UTF-8, støder på en byte, der starter med 1, tæller det, hvor mange 1 der følger, før de støder på en 0. ... Så en byte af formen 110xxxxx siger, at de første fem bits af et Unicode-tegn er gemt i slutningen af denne byte, og resten af bitene kommer i den næste byte.
Hvordan løser jeg Unicode-problemer?
Det første skridt mod at løse dit Unicode-problem er at stoppe med at tænke på typen< 'str'> som lagring af strenge (dvs. sekvenser af menneskeligt læsbare tegn, a.k.-en. tekst). I stedet skal du tænke på typen< 'str'> som en container til bytes.
Hvilke tegn er ikke tilladt i UTF-8?
Bemærk, at et byteordermærke (BOM) U + FEFF, også kaldet nul bredde no-break space (ZWNBSP), ikke kan vises ukodet i UTF-8 - byte 0xFF og 0xFE er ikke tilladt i gyldig UTF-8. En kodet ZWNBSP kan vises i en UTF-8-fil som 0xEF 0xBB 0xBF, men styklisten er fuldstændig overflødig i UTF-8.
Hvad betyder UTF-8 i HTML?
charset = UTF-8 står for Character Set = Unicode Transformation Format-8. Det er en oktet (8-bit) tabsfri kodning af Unicode-tegn. Disse bør kaste mere lys på forståelsen inden for webudvikling og scripting.
Hvorfor erstattede UTF-8 ascii?
UTF-8 erstattede ASCII, fordi den indeholdt flere tegn end ASCII, der er begrænset til 128 tegn.
Er UTF-8 det samme som Ascii?
For tegn repræsenteret af 7-bit ASCII tegnkoder svarer UTF-8-repræsentationen nøjagtigt til ASCII, hvilket muliggør gennemsigtig migrering. Andre Unicode-tegn er repræsenteret i UTF-8 ved sekvenser på op til 6 byte, selvom de fleste vesteuropæiske tegn kun kræver 2 byte3.
Hvad er forskellen mellem ANSI og UTF-8?
ANSI og UTF-8 er to tegnkodningsskemaer, der er meget udbredt på et eller andet tidspunkt. Den største forskel mellem dem er brug, da UTF-8 næsten har erstattet ANSI som det valgte kodningsskema. ... Da ANSI kun bruger en byte eller 8 bit, kan den kun repræsentere maksimalt 256 tegn.
Hvorfor bruges UTF-8?
Hvorfor bruge UTF-8? En HTML-side kan kun være i en kodning. Du kan ikke kode forskellige dele af et dokument i forskellige kodninger. En Unicode-baseret kodning som UTF-8 kan understøtte mange sprog og kan rumme sider og formularer i enhver blanding af disse sprog.
Hvad UTF-8 betyder?
UTF-8 Grundlæggende. UTF-8 (Unicode Transformation – 8-bit) er en kodning defineret af International Organization for Standardization (ISO) i ISO 10646. Det kan repræsentere op til 2.097.152 kodepunkter (2 ^ 21), mere end nok til at dække de nuværende 1.112.064 Unicode-kodepunkter.